Conformal Arbitrage - Risk-Controlled Balancing of Competing Objectives in Language Models
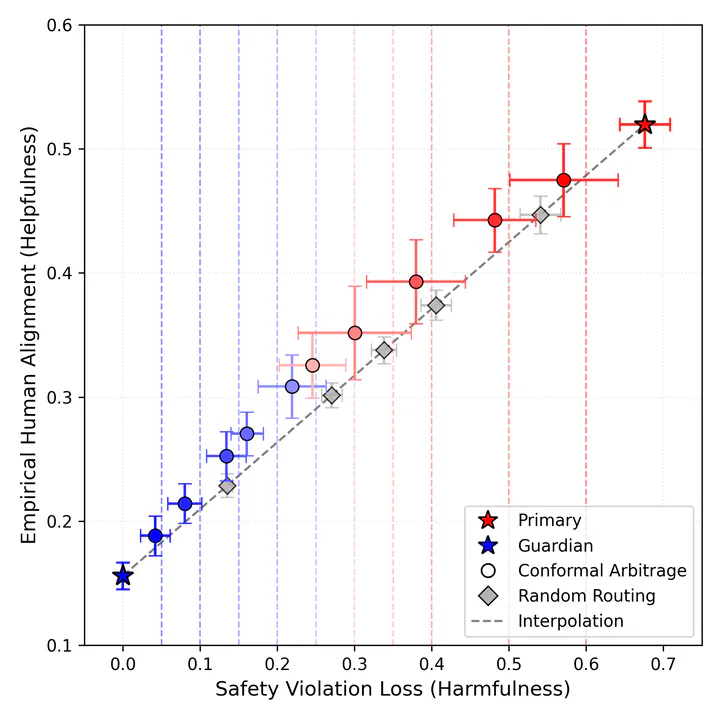 Plot of helpfulness versus harmlessness showing that we can use Conformal Arbitrage to trace a more efficient frontier of tradeoffs between competing objectives than baseline using only API access to language models.
Plot of helpfulness versus harmlessness showing that we can use Conformal Arbitrage to trace a more efficient frontier of tradeoffs between competing objectives than baseline using only API access to language models.Abstract
Modern language model deployments must often balance competing objectives, for example, helpfulness versus harmlessness, cost versus accuracy, and reward versus safety. We introduce Conformal Arbitrage, a post hoc framework that learns a data driven threshold to mediate between a Primary model optimized for a primary objective and a more conservative Guardian which could be another model or a human domain expert aligned with a guardrail objective. The threshold is calibrated with conformal risk control, yielding finite sample, distribution free guarantees that the long run frequency of undesirable events, such as factual errors or safety violations, does not exceed a user specified quota. Because Conformal Arbitrage operates wholly at the API level, without requiring access to model logits or updating model weights, it complements weight based alignment techniques and integrates seamlessly with existing cost aware cascades. Empirically, Conformal Arbitrage traces an efficient frontier, allowing users to define an acceptable performance level for one objective while maximizing utility in another. We observe that our method outperforms, in terms of accuracy, cost matched random routing between models. These properties make Conformal Arbitrage a practical, theoretically grounded tool for trustworthy and economical deployment of large language models across a broad range of potentially competing objectives.